首页
技术教程
建站开发
WP教程
实用技术
资源分享
源码分享
软件工具
字体分享
果粉之家
iOS游戏
iOS越狱
巨魔专用
热门活动
时间轴
+1
AI工具
投稿
开通会员
开通元气成员
成为我们的元气成员
你将拥有全站自由
无障碍的浏览和下载
这是对你探索精神的见证。
走进元气世界
体验知识的磅礴
无比的荣誉将瞬间降临。
开通元气成员
开通大元气成员
你被诚挚邀请
成为我们的大元气成员
贵为全站精英
你将成为掌控全站的导航者
享受独特的阅读盛筐
大元气成员,不仅是你的荣耀
同时也见证了你的成长之路
开始你的知识探索
迎接大元气的荣光
开通大元气成员
登录
注册
首页
技术教程
建站开发
WP教程
实用技术
资源分享
源码分享
软件工具
字体分享
果粉之家
iOS游戏
iOS越狱
巨魔专用
热门活动
时间轴
+1
AI工具
开通会员 尊享会员权益
登录
注册
找回密码
快速登录
QQ登录
微信登录
微博登录
码云登录
捐助本站
GO
全站99%的资源免费下载
蓝V认证
GO
立刻认证 全站发帖免人工审核
本站同款主题购买
NEW
极致优雅 功能强大的Wordpress主题
进入VIP专属Q群
GO
全部搭建教程都在群里~
最新源码
左右滑动可以查看更多源码哦~
更多
适用于GoAmzAI的40个精品应用 一杯奶茶钱即可拥有
付费资源
¥
16.88
源码分享
6个月前
3
3816
7
2023最新版WiFi大师专业版小程序带流量主独立版4.0.5S0009
会员专属
源码分享
6个月前
0
2060
9
php goto解密脚本源码分享 一键解密goto加密的php文件
会员专属
源码分享
6个月前
0
2179
5
2023新版在线工具网 修复重做版 无需数据库S0007
会员专属
源码分享
6个月前
0
2037
12
新版彩虹工具网源码发布 全新界面 支持插件扩展
会员专属
源码分享
6个月前
0
2094
8
2023最新版高仿互站网多套模板源码 在线源码中介交易系统S0005
会员专属
源码分享
6个月前
0
2049
13
2023新款手游账号交易平台系统源码S0004
会员专属
源码分享
6个月前
0
1986
12
一键安装 WHMCS V8.8.0 - 授权安装开心版
付费资源
¥
10
源码分享
# 1
7个月前
0
2347
14
最新版九块九进群源码 全新付费进群系统源码 支持分销 Thinkphp 全开源版S0002
会员专属
源码分享
7个月前
0
2417
12
界面美观功能强大的在线AI系统源码~S0001
会员专属
源码分享
7个月前
0
2266
5
微信公众号多域名回调系统1.3更新发布
源码分享
7个月前
2
2229
13
分享一个查询域名备案信息的python程序
付费资源
10
源码分享
7个月前
0
2006
15
彩虹外链网盘V5.5更新 新增用户系统与分块上传
源码分享
# 网盘源码
7个月前
7
2907
20
2023 最新美观的社区源码下载反编译版
付费资源
¥
10
源码分享
# 社区源码
7个月前
0
2094
14
一款代挂全开源版多接口PHP源码
付费资源
¥
10
源码分享
7个月前
0
2102
7
子比主题推广页购买页面代码
【0005】
付费资源
¥
5
源码分享
7个月前
0
2211
15
清新简洁的彩虹云商城模板源码,搭配可爱的看板娘设计!
0004
付费资源
¥
10
源码分享
7个月前
0
2029
7
fee1.8主题兼容Emlog Pro免授权版
【0001】
付费资源
¥
10
源码分享
7个月前
0
2197
10
任务地推分销推广拉新系统—任务分销神器
【0002】
付费资源
¥
10
源码分享
7个月前
0
1970
7
开源电子合同签署平台小程序源码 在线签署电子合同小程序源码 合同在线签署源码
【0003】
付费资源
¥
10
源码分享
7个月前
0
2062
11
最新软件
左右滑动可以查看更多软件哦~~
更多
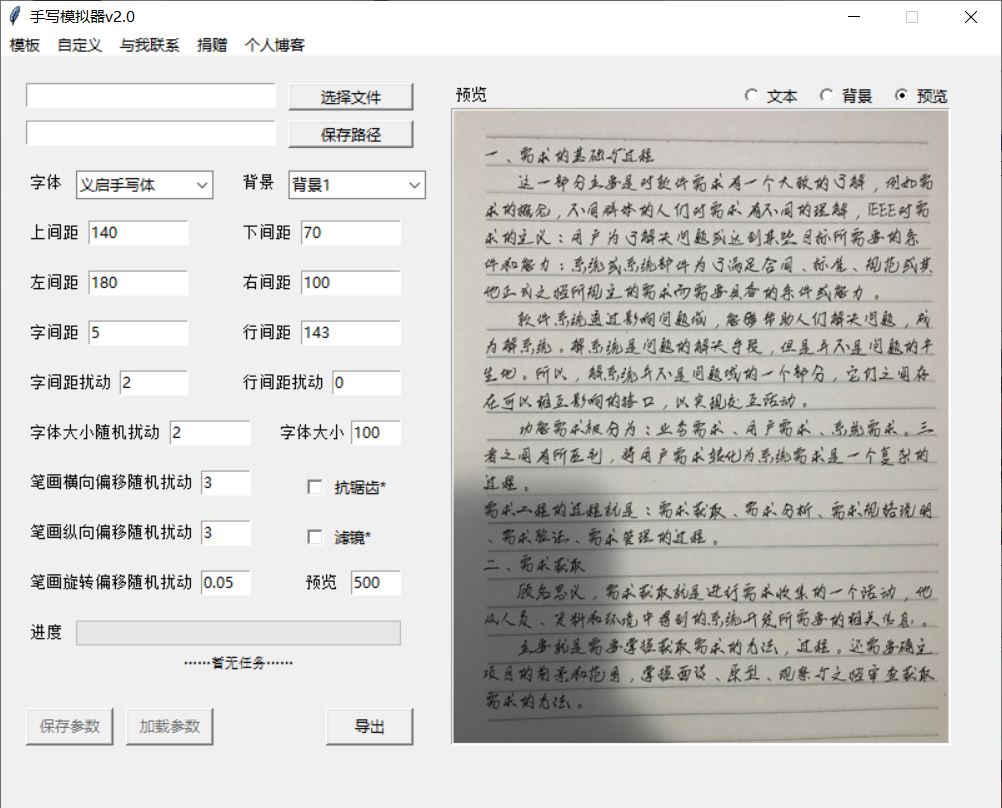
手写模拟器:享受科技的魔法,手写模拟器让电脑为你写字
会员专属
软件工具
2个月前
0
2067
7
iOS 微信输入法 1.2.2 内测已出,新增剪贴板功能
软件工具
# 越狱
# iOS
# iPhone
2个月前
0
2315
15
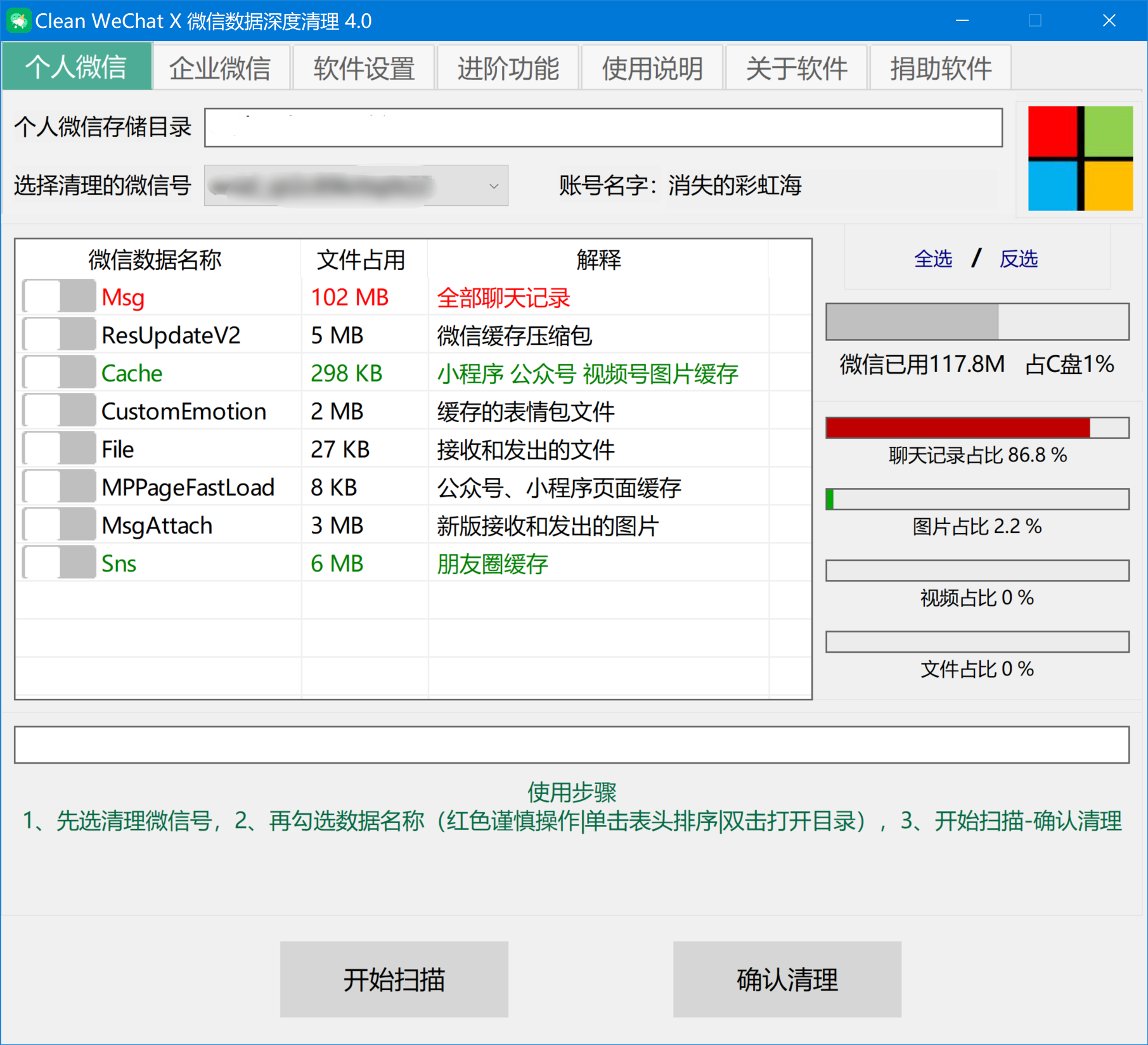
WeChat X: 微信数据的海洋清道夫
会员专属
软件工具
2个月前
0
2052
10
谷歌翻译 浏览器修复工具 2023年10月测试可用
会员专属
软件工具
6个月前
3
2115
10
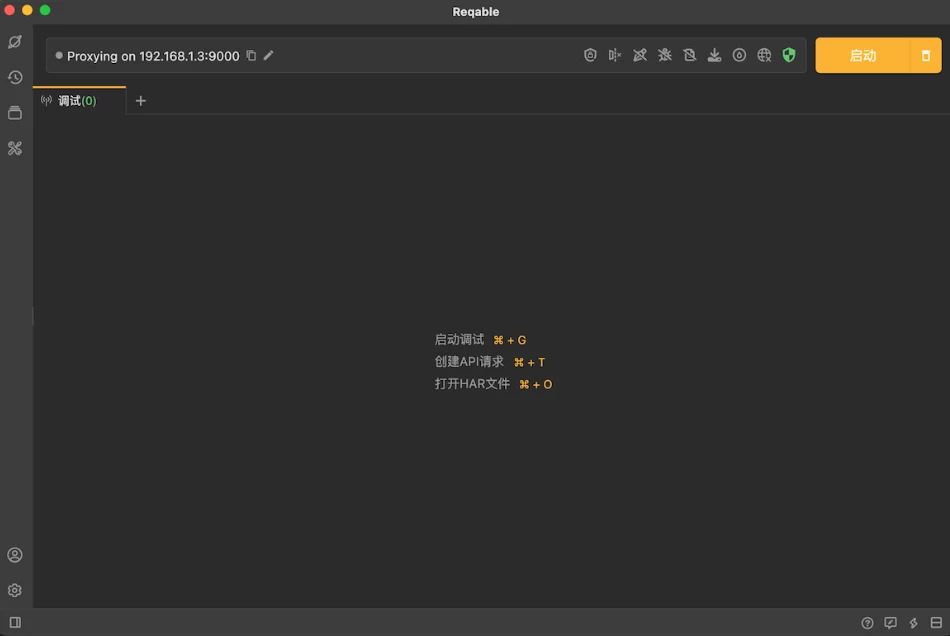
Reqable抓包工具(国产网络调试工具的春天)
付费资源
10
软件工具
# 1
7个月前
0
2150
7
360卫士C盘清理工具纯净版 C盘清理Pro
付费资源
10
软件工具
# 1
7个月前
0
2028
7
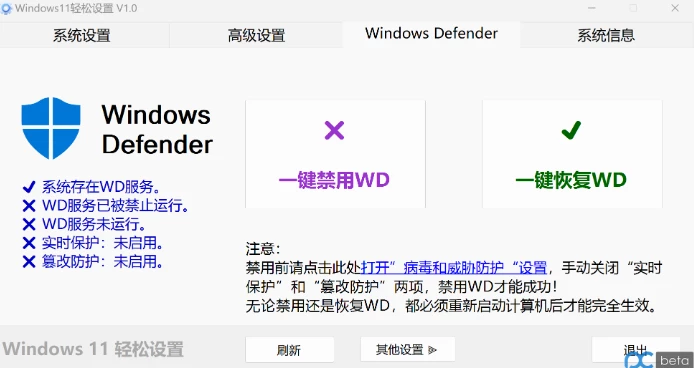
推荐一款Win11优化工具-Windows11轻松设置
付费资源
10
软件工具
# 1
# 11
7个月前
0
2102
14
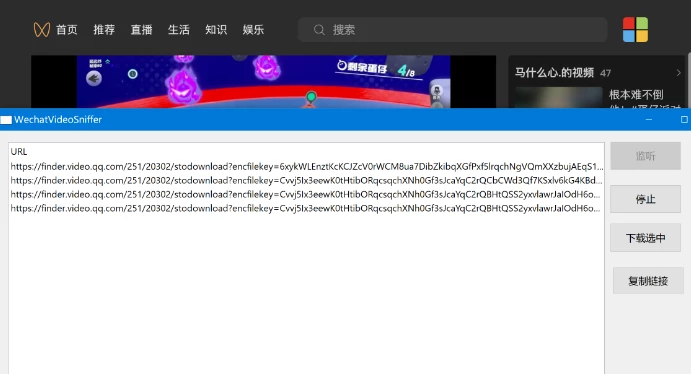
微信视频号单文件下载利器WXVideoSniffer
付费资源
300
软件工具
# 1
# QQ
7个月前
0
2115
8
微信视频号单文件下载利器WXVideoSniffer
软件工具
7个月前
0
2040
12
最新游戏
左右滑动可以查看更多iOS游戏哦~
更多
iOS游戏账号分享·聚爆(Implosion - Never Lose Hope)
价值¥7.00
会员专属
iOS游戏
7个月前
0
2010
12
iOS游戏账号分享·波西亚时光(My Time at Portia)
价值¥59.9
会员专属
iOS游戏
7个月前
0
2180
11
iOS游戏账号分享·我的世界
价值¥52.00
会员专属
iOS游戏
7个月前
0
2014
5
iOS游戏账号分享·Farming Simulator14/16/18/20
价值¥75.00
会员专属
iOS游戏
7个月前
0
2056
13
iOS游戏账号分享·海绵宝宝SpongeBob SquarePants
价值¥75.00
会员专属
iOS游戏
7个月前
0
2092
13
iOS游戏账号分享·返校 Detention
价值¥35.00
会员专属
iOS游戏
7个月前
0
2025
10
iOS游戏账号分享·如果可以回家早一点If only I could go home early
价值¥8.00
会员专属
iOS游戏
7个月前
0
2111
10
iOS游戏账号分享·口袋建造 Pocket Build
价值¥7.00
会员专属
iOS游戏
7个月前
0
1954
14
IOS游戏账号分享·我的孩子生命之泉
价值¥23.00
会员专属
iOS游戏
7个月前
0
1998
14
iOS游戏分享·军团 - Roguelite 免费下载!
价值¥8.00
会员专属
iOS游戏
iOS游戏
7个月前
0
2057
8
iOS游戏账号分享·地牢制造者+DLC Dungeon Maker : Dark Lord
价值¥29.99
会员专属
iOS游戏
7个月前
3
2260
6
越狱资讯
更多内容请移步对应分类查看
更多
好消息!iOS16.6 新越狱已发布,仅支持这些机型
速度惊人!Apple Vision Pro 开始预售,瞬间没货
iOS 16.6.1 Misaka 又更新,添加新系统支持
iOS 16.6.1 Misaka 又更新,修复此问题
来啦!iOS 17.3 RC 候选版已发布,隐私再次加强
iOS 16.6.1 Bootstrap 半越狱公测已发布
好东西!iOS17.2 奶牛工具更新,新增自定义修改
危险!iOS 16.2+ 开启监督会变砖?原因是它导致
真快!iOS 15.7.3 kfund 越狱已发布,确定可行
最新教程
左右滑动可以查看更多教程哦~
更多
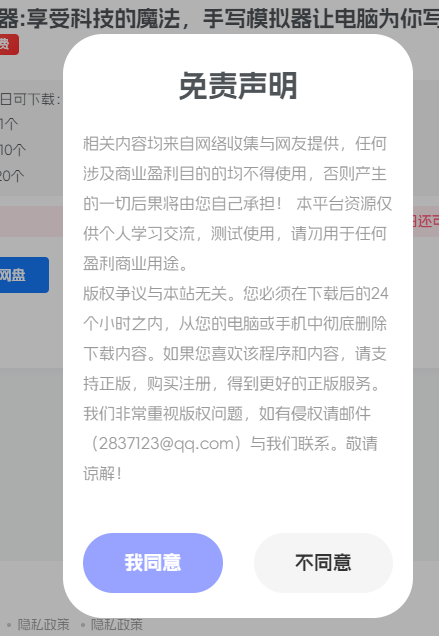
子比主题美化-下载文件时加一个版权/免责声明
WP教程
1个月前
0
2037
5
子比主题美化-给文章加一个更新时间失效提醒
会员专属
WP教程
1个月前
1
2008
5
超有用!iOS 微信 8.0.46 正式版,优化存储空间
实用技术
2个月前
0
1969
6
百度站长收回快速收录权限(原天级收录)也许加入VIP俱乐部才是归宿
建站开发
2个月前
0
2036
14
推荐一个IPv6的直播源仓库 完善的台标 几近完美的EPG节目预告
实用技术
2个月前
12
2622
8
如何利用Hosts文件防御隐私上报和广告入侵
实用技术
6个月前
0
2014
8
jsdelivr npm CDN 国内加速节点
实用技术
7个月前
0
2051
8
QQ重要功能下线 操作需谨慎
技术教程
# QQ
# QQ群
# QQ技巧
7个月前
0
2178
5
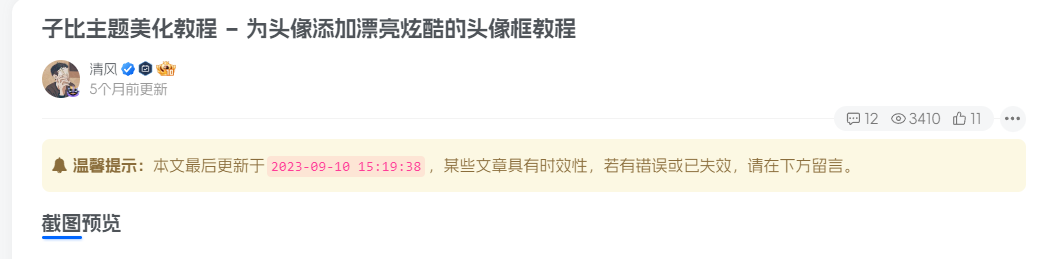
子比主题美化教程 – 为头像添加漂亮炫酷的头像框教程
WP教程
# 子比主题
# 子比主题美化
7个月前
19
3685
11
微信占用内存大?该清理垃圾了
实用技术
# 越狱
# iOS
# iPhone
7个月前
0
1975
5
GoAmzAI - 全新的AIGC应用(在线智能问答与midjourney画图工具)
建站开发
8个月前
2
946
15
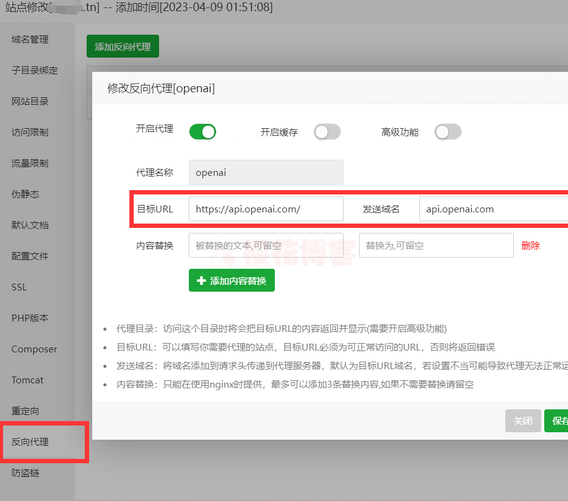
通过宝塔面板设置OpenAI反向代理官方API接口教程
建站开发
8个月前
73
1254
7
最新活动
左右滑动可以查看更多活动哦~
更多
子比主题美化-下载文件时加一个版权/免责声明
WP教程
1个月前
0
2037
5
子比主题美化-给文章加一个更新时间失效提醒
会员专属
WP教程
1个月前
1
2008
5
好消息!iOS16.6 新越狱已发布,仅支持这些机型
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
2679
6
手写模拟器:享受科技的魔法,手写模拟器让电脑为你写字
会员专属
软件工具
2个月前
0
2067
7
iOS 微信输入法 1.2.2 内测已出,新增剪贴板功能
软件工具
# 越狱
# iOS
# iPhone
2个月前
0
2315
15
速度惊人!Apple Vision Pro 开始预售,瞬间没货
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
1964
10
iOS 16.6.1 Misaka 又更新,添加新系统支持
会员专属
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
2146
12
iOS 16.6.1 Misaka 又更新,修复此问题
会员专属
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
2161
9
来啦!iOS 17.3 RC 候选版已发布,隐私再次加强
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
1996
7
iOS 16.6.1 Bootstrap 半越狱公测已发布
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
2414
15
好东西!iOS17.2 奶牛工具更新,新增自定义修改
会员专属
iOS越狱
# 越狱
# iOS
# iPhone
2个月前
0
2560
7
超有用!iOS 微信 8.0.46 正式版,优化存储空间
实用技术
2个月前
0
1969
6
WechatBakTool:你的微信聊天记录的安全守卫
会员专属
资源分享
2个月前
0
2250
8
百度站长收回快速收录权限(原天级收录)也许加入VIP俱乐部才是归宿
建站开发
2个月前
0
2036
14
WeChat X: 微信数据的海洋清道夫
会员专属
软件工具
2个月前
0
2052
10
推荐一个IPv6的直播源仓库 完善的台标 几近完美的EPG节目预告
实用技术
2个月前
12
2622
8
免费领取语雀6个月专业版会员
热门活动
6个月前
0
2256
15
如何利用Hosts文件防御隐私上报和广告入侵
实用技术
6个月前
0
2014
8
适用于GoAmzAI的40个精品应用 一杯奶茶钱即可拥有
付费资源
¥
16.88
源码分享
6个月前
3
3816
7
谷歌翻译 浏览器修复工具 2023年10月测试可用
会员专属
软件工具
6个月前
3
2115
10
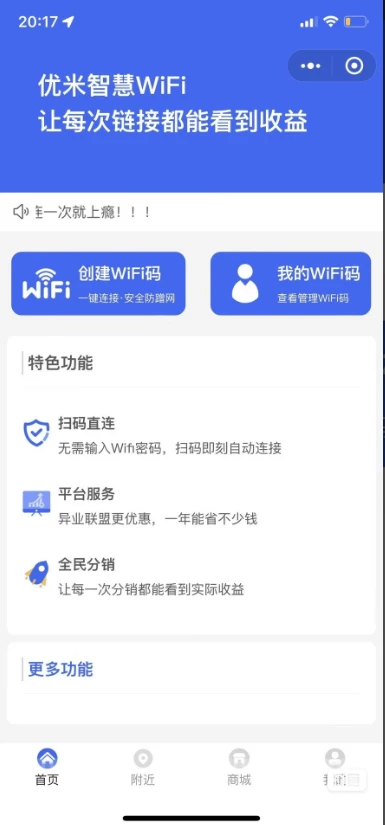
2023最新版WiFi大师专业版小程序带流量主独立版4.0.5S0009
会员专属
源码分享
6个月前
0
2060
9
php goto解密脚本源码分享 一键解密goto加密的php文件
会员专属
源码分享
6个月前
0
2179
5
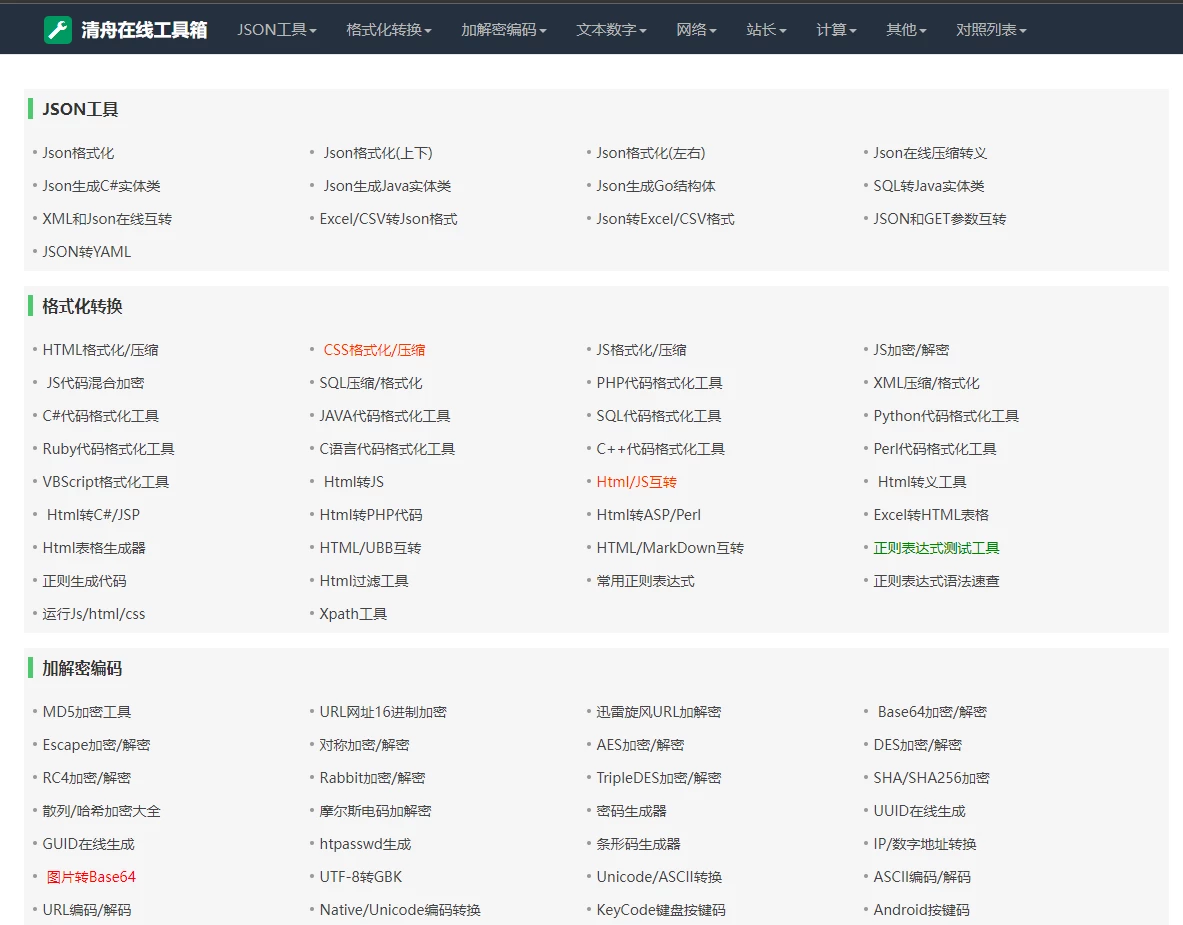
2023新版在线工具网 修复重做版 无需数据库S0007
会员专属
源码分享
6个月前
0
2037
12
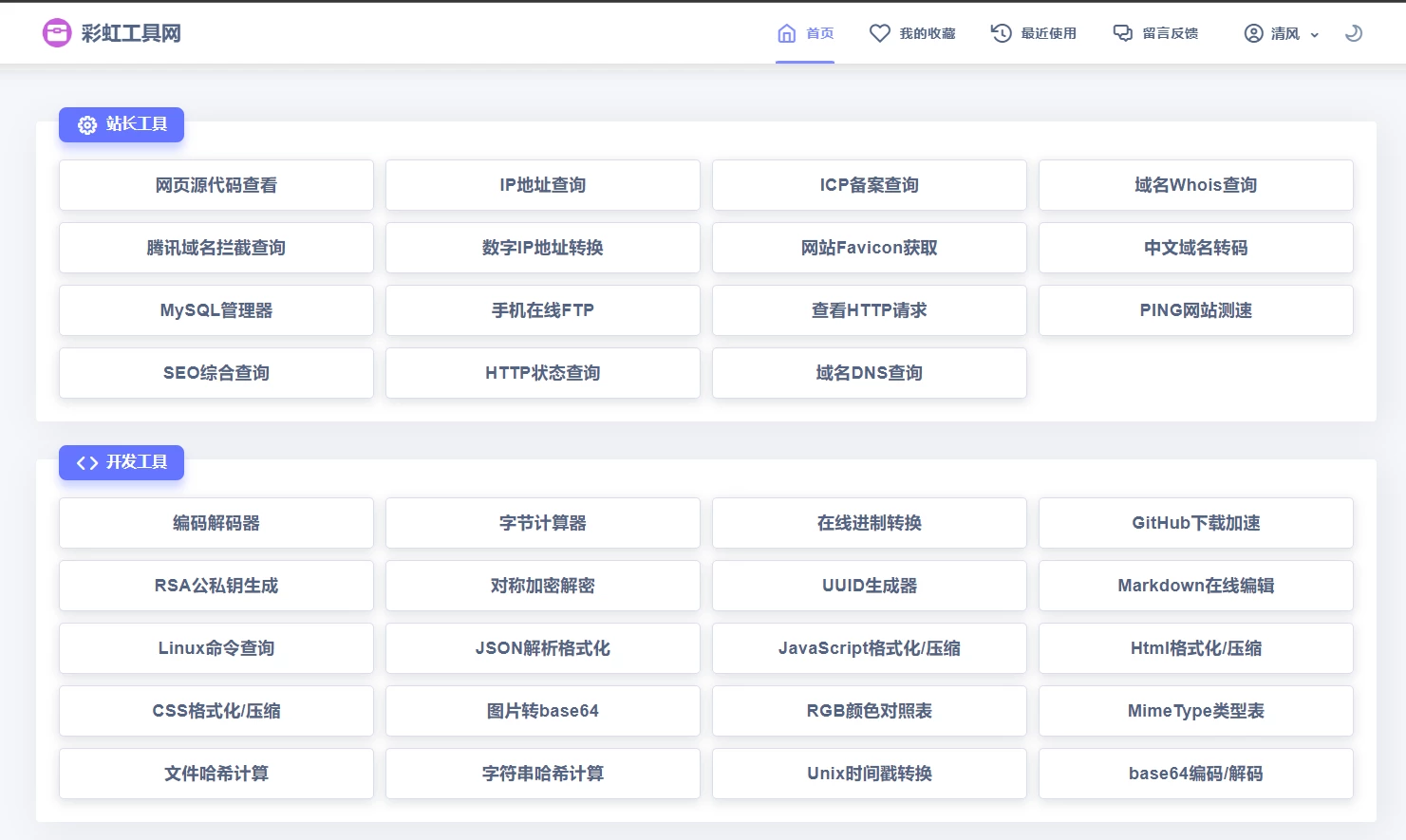
新版彩虹工具网源码发布 全新界面 支持插件扩展
会员专属
源码分享
6个月前
0
2094
8
2023最新版高仿互站网多套模板源码 在线源码中介交易系统S0005
会员专属
源码分享
6个月前
0
2049
13
2023新款手游账号交易平台系统源码S0004
会员专属
源码分享
6个月前
0
1986
12
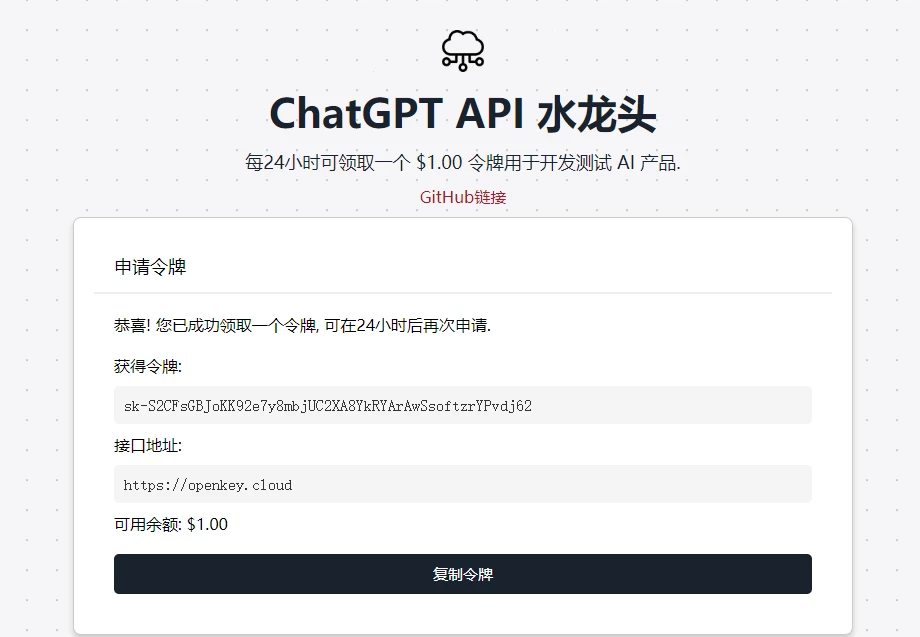
ChatGPT4.0免费分享!无限领取余额 $1.00 令牌用于开发测试 AI 产品
热门活动
# 1
7个月前
12
2394
7
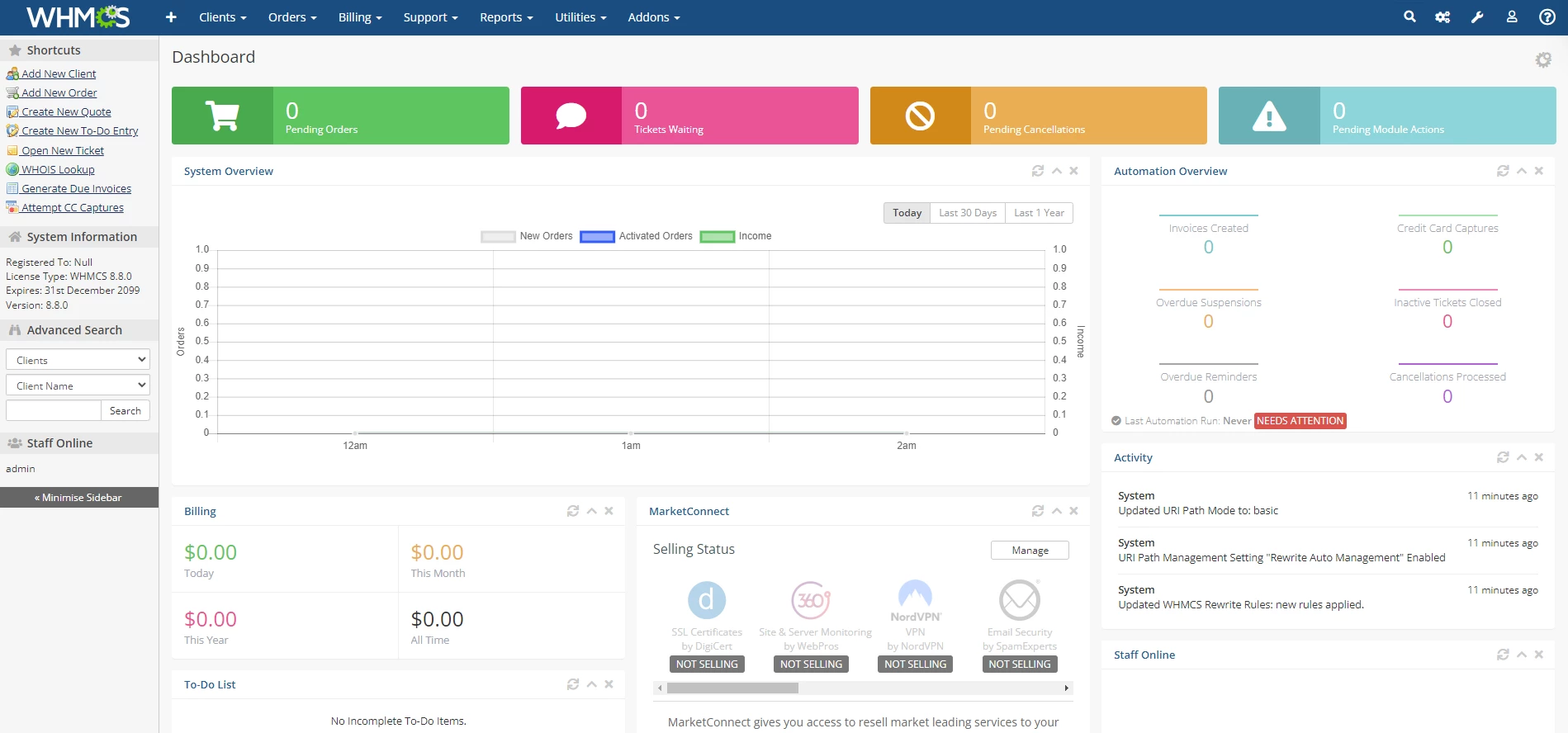
一键安装 WHMCS V8.8.0 - 授权安装开心版
付费资源
¥
10
源码分享
# 1
7个月前
0
2347
14
最新版九块九进群源码 全新付费进群系统源码 支持分销 Thinkphp 全开源版S0002
会员专属
源码分享
7个月前
0
2417
12
Reqable抓包工具(国产网络调试工具的春天)
付费资源
10
软件工具
# 1
7个月前
0
2150
7
360卫士C盘清理工具纯净版 C盘清理Pro
付费资源
10
软件工具
# 1
7个月前
0
2028
7
推荐一款Win11优化工具-Windows11轻松设置
付费资源
10
软件工具
# 1
# 11
7个月前
0
2102
14
微信视频号单文件下载利器WXVideoSniffer
付费资源
300
软件工具
# 1
# QQ
7个月前
0
2115
8
Z-Library 电子书下载 网页版 / 不用登陆账号 / 无每日下载限制
热门活动
# 1
7个月前
0
8993
9
界面美观功能强大的在线AI系统源码~S0001
会员专属
源码分享
7个月前
0
2266
5
微信视频号单文件下载利器WXVideoSniffer
软件工具
7个月前
0
2040
12
微信公众号多域名回调系统1.3更新发布
源码分享
7个月前
2
2229
13
jsdelivr npm CDN 国内加速节点
实用技术
7个月前
0
2051
8
分享一个查询域名备案信息的python程序
付费资源
10
源码分享
7个月前
0
2006
15
[亲测]鹊凿数字版权服务平台 免费申请作品数字版权 AIGC认证 在线区块链存证
热门活动
7个月前
1
2189
10
iOS游戏账号分享·Farming Simulator14/16/18/20
价值¥75.00
会员专属
iOS游戏
7个月前
0
2056
13
iOS游戏账号分享·海绵宝宝SpongeBob SquarePants
价值¥75.00
会员专属
iOS游戏
7个月前
0
2092
13
iOS游戏账号分享·返校 Detention
价值¥35.00
会员专属
iOS游戏
7个月前
0
2025
10
iOS游戏账号分享·如果可以回家早一点If only I could go home early
价值¥8.00
会员专属
iOS游戏
7个月前
0
2111
10
iOS游戏账号分享·地牢制造者+DLC Dungeon Maker : Dark Lord
价值¥29.99
会员专属
iOS游戏
7个月前
3
2260
6
iOS游戏账号分享·口袋建造 Pocket Build
价值¥7.00
会员专属
iOS游戏
7个月前
0
1954
14
IOS游戏账号分享·我的孩子生命之泉
价值¥23.00
会员专属
iOS游戏
7个月前
0
1998
14
QQ重要功能下线 操作需谨慎
技术教程
# QQ
# QQ群
# QQ技巧
7个月前
0
2178
5
彩虹外链网盘V5.5更新 新增用户系统与分块上传
源码分享
# 网盘源码
7个月前
7
2907
20
2023 最新美观的社区源码下载反编译版
付费资源
¥
10
源码分享
# 社区源码
7个月前
0
2094
14
最新字体
左右滑动可以查看更多字体哦~
更多
暂无内容
本站同款AI程序
GoAmzAI是一款强大且漂亮优雅的AIGC应用程序,功能强大,配置简单。
查看详情
在手机上浏览此页面
登录
没有账号?立即注册
手机号或邮箱
验证码
发送验证码
记住登录
账号密码登录
登录
用户名/手机号/邮箱
登录密码
记住登录
找回密码
|
免密登录
登录
社交账号登录
QQ登录
微信登录
微博登录
码云登录
使用社交账号登录即表示同意
用户协议
、
隐私声明
注册
已有账号,立即登录
设置用户名
手机号
验证码
发送验证码
设置密码
注册
已阅读并同意
用户协议
、
隐私声明
扫码登录
使用
其它方式登录
或
注册
扫码登录
扫码登录即表示同意
用户协议
、
隐私声明








































![[亲测]鹊凿数字版权服务平台 免费申请作品数字版权 AIGC认证 在线区块链存证-清舟网](https://img.qizs.cn/2023/09/d2b5ca33bd20230912052123.png)

 会员专属
会员专属